The NSF NCAR Data Commons Initiative
By Leigh Harney

GDEX Geoscience Data Exchange
The Geoscience Data Exchange (GDEX) is NSF NCAR’s universal, high-quality, analytics-ready platform, designed as part of Phase 2 of the NSF NCAR Data Commons Initiative. CISL is integrating priority datasets from all labs into GDEX to transform how scientists access, analyze, and share data. GDEX provides analysis-ready datasets and unparalleled compute power, custom-built to position your data for AI/ML breakthroughs and ensure it is findable and usable today.
GDEX was built for researchers. By putting your data on GDEX, researchers gain visibility, discoverability, and the ability to collaborate across labs and disciplines. GDEX enables you to run analytics at scale with NSF NCAR’s world-class computing resources, replacing isolated workflows. GDEX unifies scattered datasets into one reliable platform: empowering scalable, collaborative science.
For leadership, investing in GDEX means investing in the next generation of community science—making complex data accessible, interoperable, and impactful. GDEX is a critical step toward AI-ready Earth system science, accelerating insights across disciplines. It provides a shared, scalable infrastructure that reduces duplication of effort and lowers costs.
For the general public, GDEX is a unified data commons: a platform where individuals' data contribute to collective discoveries that would be impossible to achieve alone. GDEX sets the new standard for high-quality, analytics-ready data, unlocking collaboration, efficiency, and innovation across the geosciences community.
Why Use GDEX?
GDEX fosters a larger, integrated analytics ecosystem by:
- Unlocking new analysis: Enables advanced analytics and AI/ML workflows previously impossible with scattered or siloed systems.
- Connecting directly to compute: Integrates data with NSF NCAR’s world-class, community accessible computing resources (Derecho, Casper, CIRRUS) to eliminate bottlenecks and enable faster, larger-scale science.
- Streamlining your workflow: Delivers analysis-ready datasets and standardized formats, reducing time spent on data preparation.
- Enhancing platform design: Rebuilt on Kubernetes with metadata-rich structures for easier searching, filtering, and integrating datasets.
- Democratizing access: Unites and opens previously scattered datasets to the entire research community, providing access to more high-quality data.
- Reducing redundancy and risk: Runs on HPC-grade systems for reliability, lowering duplication of effort, and eliminating the need for multiple mini-clusters.
- Scaling seamlessly: Handles large, complex datasets and connects to powerful APIs for reproducible, automated, and scalable analyses.
- Fostering collaboration: A unified data commons enables finding, sharing, and building on others’ work, accelerating insights across labs and disciplines.
- Lowering costs and effort: Shared, centrally supported infrastructure saves labs time and expense from maintaining parallel systems.
How GDEX Was Custom-Designed for You
- Kubernetes platform: Provides a reliable, scalable, and fault-tolerant foundation with consistent uptime and seamless performance.
- Enhanced metadata framework: Facilitates easy discovery, filtering, and integration of datasets.
- Optimized data formats: Allows direct movement into analysis, machine learning, and advanced workflows.
- Interoperable APIs: Enable automation, reproducibility, and integration with modern tools, notebooks, and AI/ML pipelines.
- Centralized infrastructure: Eliminates siloed clusters and hidden data, providing a scalable, shared system.
- Unified data access paths: Offers efficient, consistent structures for data interaction.
- Colocated data with compute: (CASPER, Derecho, CIRRUS) Supports large-scale analytics without downloading massive files.
- Engineered for efficiency and resilience: Built on HPC-grade infrastructure to reduce redundancy and increase reliability.
- Aligned with FAIR data principles: Democratizes access for the entire research community.
Submit Your Data
GDEX wants the data you analyze to integrate it into this exceptional new analytics platform!
- Think broadly: Consider internal and external products, datasets used by many researchers, and collections that would benefit most from wider access.
- What datasets would be most beneficial to your research?
- What datasets would be most beneficial to NSF NCAR and the research community?
- Please send us your priority dataset information so we can prioritize it for GDEX. Include: type, size, current usage, and resources needed, etc.
Casper Integration: Don't Let Your Data Hide
Casper is becoming the central place for data access, analysis, and collaboration. In the old Casper the Friendly Ghost movies, Casper was always about bringing people together, not hiding in the attic. That’s precisely the spirit of this effort: shared resources, shared discovery.
CISL’s allocations team has set up a new allocated project for each lab titled "Data Analysis on Casper" to simplify access and make Casper the clear, supported space for shared analysis and collaboration. This project provides an easy way to access the new analysis and computing power of GDEX, regardless of a specific project association.
Why Use Casper?
- Avoid your own clusters: Save labs money and staff time by using Casper instead of maintaining scattered, local compute systems.
- Share and integrate across labs: Casper pulls datasets and tools into one place, breaking silos and making collaboration easier.
- Recoup cost and effort: Centralized, scalable HPC resources like Casper save resources compared to maintaining local systems.
- Discoverability: Data and tools on Casper become visible and usable across NSF NCAR.
What do YOU need to do to channel Casper?
Unless requested, this project will not include Casper-GPU allocations. (Note: this project will also not include Derecho allocations.)
Don’t ghost great data. Confirm or create your Casper account today!
- Check your account: If you work on data analysis, confirm you have Casper access and can access the "Data Analysis on Casper" project. If not, please reach out to your allocation representative or email allocreps@ucar.edu.
- Stay tuned: Training opportunities and roadshows are coming soon.
- Need help? The CSG team is here! Please contact Ben Kirk (benkirk@ucar.edu) or Doug Schuster (schuster@ucar.edu) with any questions.
Who to Contact?
Questions? Contact Doug Schuster (schuster@ucar.edu) or the NSF NCAR Research Data Help Desk (datahelp@ucar.edu | datahelp.ucar.edu).
A Major Milestone for NSF NCAR: The GDEX Transition is Complete
As of Tuesday, September 9, the Research Data Archive (RDA) has been relaunched as the Geoscience Data Exchange – Integrated Research Data Commons (GDEX).
GDEX democratizes data access through adherence to FAIR principles, a shared infrastructure integrated with NSF NCAR HPC (Casper and Derecho), national-scale data and compute services, standardized formats, and metadata-rich infrastructure. Creating analysis-ready datasets prepares NSF NCAR for AI/ML growth, standard data models, and interoperable APIs that will enable faster, cross-domain insights.
Discover the benefits of using GDEX:
- Connect with streamlined, analysis-ready resources built to support your research.
- Place your data where others can find it, and in return, discover newly shared datasets that connect directly to your own work.
- Access NSF NCAR's national-scale data and compute power (Derecho, Casper, CIRRUS) alongside your data.
- Create and test AI/ML models more easily with FAIR principle standardized formats and metadata-rich infrastructure.
- Search in a single, unified location to discover cross-domain, analysis-ready datasets that were once scattered and hard to find.
- Engage with your scientific community with new streamlined and remote delivery options.
- Create your own analysis-read datasets with cross-domain insights.
GDEX is a platform built for collaborative growth, designed and created by a united team from NSF NCAR's Computational and Information Systems Lab (CISL), for everyone to share data and models in order to power discovery, connection, and collaboration.
By any count, this has been a tremendous milestone, with 960 dataset collections transferred, approximately 20 staff members directly involved, 9 petabytes of data migrated, and 500 support tickets transitioned from DASH Help to the new Research Data Help Desk.
This milestone is a celebration not just of technical success, but of the collaborative spirit that defines NSF NCAR. We are grateful to everyone who played a role in making this possible:
- CISL's cloud team (called CIRRUS), data management teams (SAGE and DECS) — all aspects of the transition
- Climate and Global Dynamics Laboratory (CGD) — Teagan King — leadership in Climate Data Gateway Migration
- FLPO — Leigh Harney — project management, communications, and coordination
What's next? Your input will shape where GDEX goes next! The team is actively building:
- Improved user experience and data curation tools guided by Lab Data Curator feedback.
- Smarter programmatic search and integration with LLM-powered interfaces.
- AI-ready resources including optimized datasets and example workflows like Pythia cookbooks.
- New Science Gateway(s) to streamline data exploration and analysis.
- Add more curated datasets to the collection, starting with prioritized Earth Observing Laboratory (EOL) and High Altitude Observatory (HAO) datasets, and datasets that you request.
Interested? Here's how you can help: Try it out and tell us what you need. Your feedback drives the next round of features and capabilities. Also, share your data to upload into this collaborative platform to make it discoverable across the community.
Please join us in applauding the Data Commons team, and in exploring the new GDEX!
Timeline: NSF NCAR Data Commons Final Stretch!
The NSF NCAR Data Commons efforts have all entered their final phases. This cross-lab effort is transforming how we manage, integrate, and share data: enabling AI/ML readiness, interdisciplinary collaboration, and long-term scientific discovery.
What’s happening?
The Climate Data Gateway (CDG) and legacy Geoscience Data Exchange (GDEX) have been consolidated into a modernized, infrastructure-reinforced Research Data Archive (RDA).
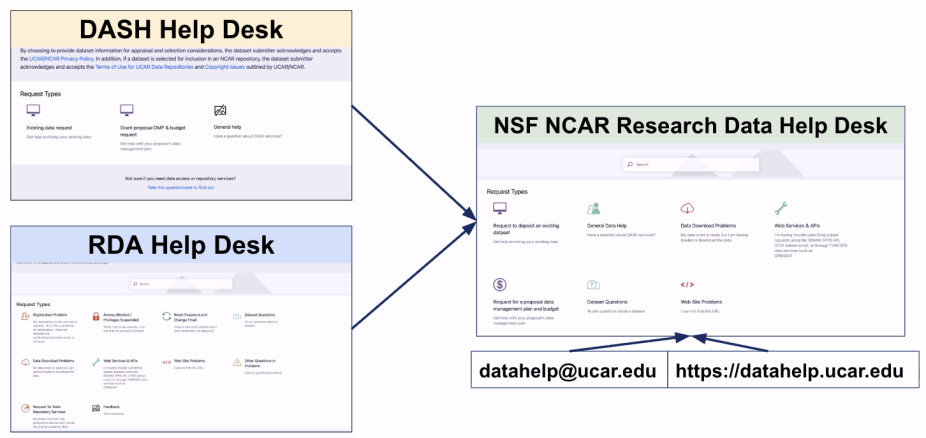
August 25, 2025: Help Desks merge.
- On Monday, August 25th, the DASH and RDA help desks will merge into the NSF NCAR Research Data Help Desk (datahelp@ucar.edu|datahelp.ucar.edu), which will be monitored by Data Engineering and Curation Services staff. Legacy tickets and emails have been migrated to retain history.

On Wednesday, August 27, the migration is complete. On Tuesday, September 9, the RDA is rebranded as GDEX.
- On Wednesday, August 27th, legacy CDG and GDEX will be retired as all data is now available in the unified RDA.
- On Tuesday, September 9th, the RDA will officially relaunch as NSF NCAR’s Geoscience Data Exchange – Integrated Research Data Commons (GDEX), complete with rebranding, updated websites, new data access paths (e.g., /gdex/data/<dataset>), and updated file naming conventions.
Why is it important?
This democratizes data access through adherence with FAIR principles, a shared infrastructure integrated with national-scale data and compute services, standardized formats, and metadata-rich infrastructure. Creating analysis-ready datasets prepares NSF NCAR for AI/ML growth, standard data models, and interoperable APIs that will enable faster, cross-domain insights.
- Delivering consistent access for all researchers
- Supporting AI/ML and advanced workflows
- Applying FAIR, resilient, and certified infrastructure
- Enabling data-proximate compute on NSF NCAR systems (Derecho, Casper, CIRRUS)
- Providing streaming and remote delivery options for the broader community
- Creating analysis-ready datasets that accelerate cross-domain insight
- This shift improves discoverability: both NSF NCAR compute users and external researchers will gain easier, more consistent access through direct read or streaming optins
This effort sets the stage for future integration of datasets curated across NSF NCAR labs—building a unified, AI-ready foundation for scientific discovery.
What's next?
Following the September relaunch, the team will continue to expand GDEX capabilities, including:
- Improved user experience and data curation tools (guided by Lab Curator feedback)
- Enhanced programmatic search and integration with LLM-powered UIs
- Development of AI-optimized datasets and published example workflows (e.g., Pythia cookbooks)
- New Science Gateway(s) to streamline data exploration and analysis
- Integration of additional NSF NCAR curated datasets, starting with prioritized EOL and HAO collections
For inquiries or opportunities to get involved, please contact Doug Schuster.
Written by Leigh Harney
Democratizing Data According to FAIR Principles
The merged system will provide a metadata-rich, standards-aligned foundation designed to make data more findable, accessible, interoperable, and reusable (FAIR). It supports everything from model development to AI training and enables the AI/ML roadmap by delivering consistent, high-quality inputs for next-generation science.
This work strengthens operational resilience, promotes efficiency, and lays the foundation for shared services, interoperable APIs, and unified data models—reducing silos and accelerating insights across disciplines.
Vision

The Data Commons Initiative advances FAIR data access by establishing shared infrastructure, standardized formats, and metadata-rich services.
An Integrated, FAIR-Driven Data Ecosystem for Earth System Science
The overarching goal of the Data Commons is to enable scalable, analysis-ready access to scientific data through a cohesive, standards-based data infrastructure. This work will position NSF NCAR to support current and future research needs by reducing fragmentation and improving cross-domain data use.
Core Capabilities and Benefits
The Data Commons initiative delivers more than just centralized storage—it is a forward-looking platform designed to accelerate discovery, democratize data access, support reproducible science, and empower AI/ML-driven research.
- Unified Data Access: A single, structured entry point for curated datasets from across NSF NCAR integrated with the distributed access capabilities of the Open Science Data Federation.
- Discovery-Driven Design: Standardized, interoperable metadata enhances data discovery, cross-domain reuse, and streamlined access to research outputs.
- Analysis-Ready Infrastructure: Supports high-performance processing, advanced workflows, and AI-assisted tools like automated coding and workflow generation.
- Augmented Search and Documentation: Intelligent services surface related datasets, models, and publications—while assisting with metadata validation, workflow documentation, and governance flagging.
- AI/ML Enablement: Structured data environments support the training and validation of AI/ML models, enabling improved Earth system simulations, smarter data mining, and advanced pattern recognition (e.g., recommending related datasets via trained models).
- Operational Resilience: Built on containerized infrastructure for scalability and uptime. Supports rapid deployment, disaster recovery, automated testing, and streamlined updates.
- Trust and Reuse: A consistent metadata standard ensures reproducibility and benchmarking across domains and institutions. All services align with FAIR principles and community governance practices to support responsible data stewardship.
What’s Next?
Following the September relaunch, the team will continue to expand GDEX capabilities, including:
- Improved user experience and data curation tools (guided by Lab Data Curator feedback)
- Enhanced programmatic search and integration with LLM-powered UIs
- Development of AI-optimized datasets and published example workflows (e.g., Pythia cookbooks)
- New Science Gateway(s) to streamline data exploration and analysis
- Integration of additional NSF NCAR curated datasets, starting with prioritized EOL and HAO collections
For inquiries or opportunities to get involved, please contact Doug Schuster.
Written by Leigh Harney